Critical Render Path. Tutorial
Hi! I'm Nik and I'm a frontend developer. Besides writing code, I was a mentor at HeadHunter's developers school: https://school.hh.ru/
We recorded our lectures in 2018-2019. These lectures are opened on our YouTube channel (but in Russian). Here is a playlist https://www.youtube.com/watch?v=eHWMtfqxjes&list=PLGn25JCaSSFQQOab_xMXI3vJ0tDUkFaCI However, in 2019-2020 school we didn't record our lectures. I had a talk dedicated to frontend performance optimization. After it, I decided to make an article based on the material. As the lecture was 3 hours long, I divided the article into 2 parts.
This longread could be useful as a handbook. We will cover:
- Why performance is important;
- FMP (First Meaningful Paint), TTI (Time To Interactive);
- Critical render path, DOM, CSSOM, RenderTree;
- Base steps to improve performance.
The rest of the themes, which were in my lecture, will be in the second article. The second part will cover such topics as layout, reflow, repaint, composite, and their optimization.
Why performance is important. Motivational part.
0.1 seconds — it is a gap when we perceive a connection between our mouse click or keyboard press and changes in the application or interface.
I think almost everybody saw a lag when you input a text, but the interface handles only a previous word. A similar problem exists with button clicks. The good UX helps me, it tells me: "Okay, just a moment and everything will be done". The latest example I had was when I tried to remove a huge number of emails through a web-version in one email webapp (let it be an anonymous service). When I selected emails and clicked the "remove" button, nothing happened. At those moments I didn't understand either I misclicked or the interface had a lag. The second variant was correct :) It is frustrating. I want to have a responsive interface.
Why should it be 0.1 seconds? The key is that our consciousness makes connections between our actions and the definite changes in the website and 100ms is a good time for it.
Let me show an example. Here is a video clip of 30 Seconds to mars — Hurricane (be careful, it is an explicit one, and has some NSFW parts. You can open the clip on 9:30 and you will be able to catch frames, which we are talking about, during the next 30 seconds): https://www.youtube.com/watch?v=MjyvlD0TwiA this clip has several moments when a screen appears for only 1-2 frames. Our consciousness not only handles this screen but recognizes content (partly).
1 second is a perfect time to load a site. Users perceive surfing smoothly in this case. If your service could be loaded within 1 second you are awesome! Unfortunately, we have a different situation in general.
Let's count what we have to do when a user navigates to our site: network outgoings, backend processings, microservice queries (usually), DB queries, templating, data processing on the client-side (we are going to talk about it today), static resource loading, script initialization. Summing up: it's painful.
That's why usually 1 second is ideal timing.
10 seconds. Lots of analytics tell us that people spend about 30 seconds visiting a website on average. A site that is loaded 5 seconds consumes 1/6 of user time. 10 seconds — a third.
The next numbers are 1 minute and 10 minutes. 1 minute is a perfect time to complete a small task using a site like reading product info or getting registered. Why should it be only a minute? We don't spend much time these days concentrating on one thing. We change objects of our attention pretty often.
- Opened an article, read the tenth part of it, then a colleague sent a meme on Slack, web-site trigger alerted, wow coronavirus news, all of it. Only in the evening, you get time to read an article.
When a user spent 10 minutes on a site, it means they tried to solve their problem at least. They compared plans, made an order, etc.
Big companies have good analytics for performance metrics:
- Walmart: 1 second means + 2% conversion
- Amazon: 0,1 seconds increase proceeds for 1%
The latest motivator is from Wikipedia:
https://twitter.com/wikipedia/status/585186967685619712

Let's go further:
Two eternal questions
Let's run a lighthouse check on hh.ru. Looks pretty bad (pay attention it's a mobile configuration of the lighthouse):

Here we have 2 traditional questions:
1) Who's to blame for this? :) (and it's better to replace with a question why we have this)
2) What do we do with it?
Spoiler: there won't be a picture of how good our metrics became at the end.
Let's dive
We have 3 common scenarios:
- First paint
- Page processing (user clicks, data input, etc.)
- SPA — changing pages without reloading
Talking about first-page loading, we have 2 the most important stages of page readiness from the user's point of view: FMP (First Meaningful Paint) and TTI (Time to interactive):
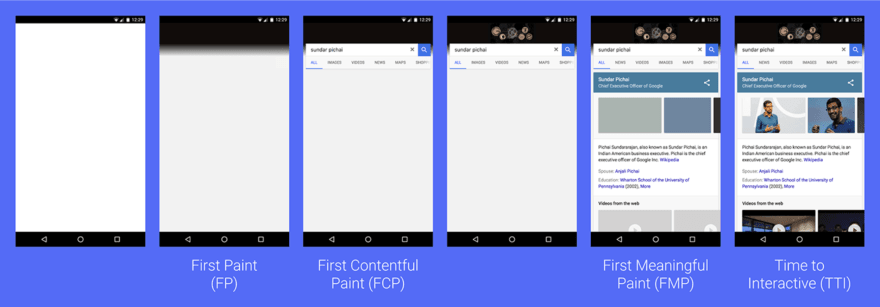
FMP for users indicates that we have text, and they can start consuming content (of course in case you are not Instagram or youtube).
TTI === the site is ready to work. Scripts are downloaded, initialized, all resources are ready.
The most important metric for HeadHunter (hh.ru) is FMP, as applicants base behavior is to open vacancies search and then open each vacancy in a new tab so that users can read them one by one and make a decision whether they want to apply to this vacancy or not.
With some nuances, FMP is one of the best metrics to measure websites' critical render path. A critical render path is a number of actions, resources, which should be downloaded and processed by the browser before showing a first result appropriate to users' work. Minimal resources, we have to download, are HTML, CSS stylesheets, and blocking js scripts.
Critical render path or what the browsers do to show user text
TL&DR;
0) Make a navigate request (DNS resolve, TCP request, etc.)
1) Receive HTML-doc;
2) Parse HTML
3) Build the DOM (Document object model)
4) Send requests to download blocking resources (works in parallel with the previous process)
5) Receive blocking resources, especially CSS-code. In case we have blocking JS code, execute it.
6) Rebuild the DOM if needed (especially in case blocking JS mutates DOM)
7) Make CSSOM tree
8) Build Render tree
9) Draw a page (Layout ⇒ paint ⇒ Composite)
Note: Reflow could be executed additionally on previous stages, due to the fact that js could force it. We will cover this part in the second article
In details:
Request

Make a request, resolve DNS, IP, TCP, etc. Bytes are running through the sockets, the server receives a request.
Response
Backends execute a request, write bytes into the socket. We receive the answer like this:

We receive a bunch of bytes, form a string due to the text/html data type. Interesting thing: first requests are marked by the browser as a "navigate" request. You can see it if you subscribe to fetch action in ServiceWorker. After receiving data, the browser should parse it and make DOM.
DOM processing
DOM
We receive a string or a Stream. In this stage browser parses it and transform a string into a special object (DOM):

This is only a carcass. At this point, the browser knows nothing about styles, hence it doesn't know how to render the page.
Downloading of Blocking resources
Browsers synchronously process HTML. Each resource either CSS or JS could be downloaded synchronously or asynchronously. When we download a resource synchronously we block the rest of DOM processing before we receive it. That's why people recommend putting blocking javascript without defer and async attributes right before the closing body tag.
So each time browsers get to the blocking resource, they make a request, parse the response, and so on. Here we have some limitations such as the max number of simultaneous domain requests.
After all blocking resources are received, we can form CSSOM
CSSOM
Let's suggest, besides meta and title tags we have style or link. Now browsers merge DOM and CSS and make an object model for CSS:

The left part of the object (head and the children) isn't interesting for CSSOM, as it wouldn't be shown to the user. For the rest of the nodes, we define styles, which browsers will apply.
CSSOM is important, as it helps us to form RenderTree.
RenderTree
The last step between making trees and render.
At this stage, we form a tree that will be rendered. In our example, the left part won't be rendered, so we will remove it:

This tree will be rendered.
However, we could get a question. Why do we render "RenderTree" instead of DOM? We can check it easily by opening DevTools. Even though DevTools has all DOM elements, all computed styles are based on RenderTree:

Here we selected a button in the Elements tab. We got all the computed data of the button: its size, position, styles, even inherited ones, etc.
After making the RenderTree the browser's next task is to execute Layout ⇒ Paint ⇒ Composite for our app. Once the Composite is ended user will see the site.
Layout ⇒ Paint ⇒ Composite could be a problem not only for the first render but also during user interaction with the website. it's why I moved this part to another article.
What can we do to improve FMP and TTI?
TL&DR;
1) Resource optimization:
1.1) Split blocking resources by pages both js and css. Store reusable code either into common chunks, or small separated modules;
1.2) Load what the user needs at the beginning of work with the page (very controversial part!).
1.3) Separate third-party scripts
1.4) Download images lazily
2) HTTP2.0 / HTTP3.0:
2.1) Multiplexing
2.2) Headers compression
2.3) Server push
3) Brotli
4) Cache, ETag + Service worker
Detailed*:*
Working with resources
Splitting blocking resources*. JS*
The main pain is 2 things: blocking resources and their size.
The general advice for big sites is to split blocking styles and resources by pages. All reusable code should be stored in common chunks or separated modules. For this purpose, we are able to use suppositive https://github.com/gregberge/loadable-components or https://github.com/theKashey/react-imported-component to react or any similar solution for vue, angular, and etc. In case our components import styles it becomes easy to split them too.
As a result we get:
1) Bundles with reused js modules and page ones. Splitting strategies could be varied. it's possible to make bundles that combine common code for 2 or more pages or just split whether it's page part or common with only 1 common bundle.
Better to see the difference on a scheme:
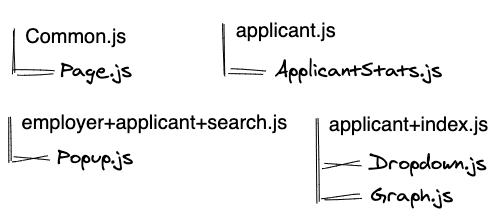
Initial arrangement:

Strategy 1 makes a dependency: module ⇒ pages that use it:
So, to load the main page (index.html) we should download 2 bundles: Common.js + applicant+index.js. /applicant page is required to load all 4 bundles. It's common to have a huge number of such chunks for big sites. In this case, it helps us to fix this problem using HTTP2.0.
Summing this strategy up:
+: Code is distributed between pages, we don't download unnecessary chunks;
+: Modules could be cached. Releases don't require to update all the bundles, only necessary ones;
-: A lot of network costs to get separated chunks. (fixed by HTTP2.0 multiplexing).
Strategy 2: store each reused module separately

Each file that is used more than in 1 page will be stored in a separate file. It means we get a tragic increase in small files. The most frustrating part is that chrome doesn't cache files which less than 1Kb. So that we are going to lose caching following this strategy.
+: Releases have the smallest influence on our users' caches;
-: The bigger amount of network costs in comparison with 1 strategy;
-: Caches could not work properly as lots of files could be less than 1 Kb. The only way to fix it is to use a Service worker. We'll talk about it below.
This strategy could be quite good, as all the cons could be solved.
Strategy 3: Store a big bundle of all modules which is used more than in 1 page:
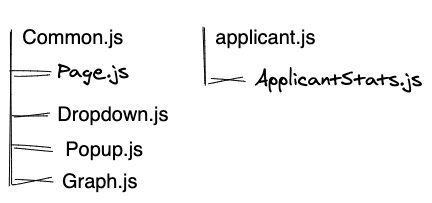
+: The smallest amount of files. Any page requires only %page%.js + Common.js;
-: Significant amount of unused js will be downloaded during the first load;
-: A high probability of losing Common.js cache after release. (as it seems, that each release is about to have changed in a module which is included by Common.js)
My advice is not to use this strategy or use it only for small websites.
But this strategy is still not as bad as the next one:
Anti-strategy 1: Each page has its own dependencies. We separate modules which are included by all the pages (common for all pages):
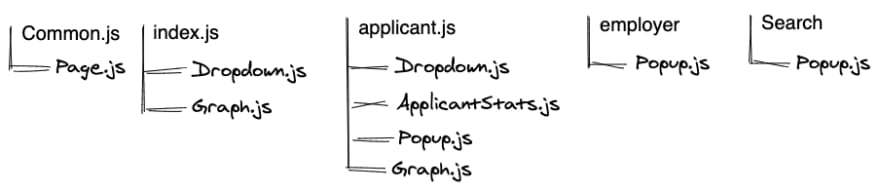
The biggest overhead we get here. When a user changes the page, they have to download modules they already have. For instance, a user opens the main page and gets 2 chunks: Common.js + Index.js. Then they authorized and navigates to the applicant page. So, Dropwon.js and Graph.js will be downloaded twice.
Please, don't do this ;)
Wrapping this up: The first two strategies are the most suitable for big websites. Likely they will have notable improvement of TTI. If you have render-blocking JS, the main question is why it's blocking. Should it block render? Try to eliminate such resources or decrease their number.
Offtopic. Why 30Kb of JS is more tragic than 30Kb of images
Suggest we have JS that animate a page and make some popups. Besides js, we have a picture of the same size (in Kb).
To run JS it's required to download the code, parse it, serialize to code which will be suitable for the interpretation, and finally execute it. So, it's why the costs of executing JS are higher than processing an image.
Splitting blocking resources. CSS
This improvement has a direct influence on FMP (of course in case you don't work with async CSS).
If you use react \ vue \ angular all the things you should do is the same as JS splitting. As for example in your react code it's likely you have direct imports:
import './styles.css'
It means during JS bundling we are able to split CSS also, following to one of the described strategies. We'll get common.css, applicant-page.css, and applicant+employer.css as well.
In case you don't have direct imports, you could try https://github.com/theKashey/used-styles to define page styles. Here is an article about this tool https://dev.to/thekashey/optimising-css-delivery-57eh.
It helps to speed up the download. For example in the case of hh.ru for almost a second according to lighthouse analytics:

Load what the user sees, not the whole page.
Likely your page has several screens, in other words a user doesn't see the whole page on their first screen. Besides it, some functions hide under the clicks, actions, etc.
The idea of optimization is to manage the resources loading process. In the beginning, load in a blocking way the CSS, which is vital to open the page. All CSS that refers to pop-ups or hidden under JS code could be loaded asynchronously, for instance, by adding rel=stylesheet from JS code or by using prefetch with onload callback. There is no general advice on how to do it. You have to check the site and find out which elements could be downloaded asynchronously.
In this case, we increase the complexity but improve the FMP metric.
Taking out third-party scripts
We do have a huge amount of 3d-party scripts at hh.ru
7 out of 10 the heaviest scripts are third-party:

What can we do with this?
- Make sure, all the resources will load asynchronously and don't have an influence on FMP
- Reduce the harmful influence to your code from ads and other things like analytics, technical support popups. You can postpone their initialization using
requestIdleCallback. This function will plan callback with the lowest priority when it wouldn't be any tasks in the queue.
This recipe allows us to retrench on FMP, but TTI will still have downgrades. As we just postpone them, to reach a better user experience.
Loading images lazily
Images affect our TTI. If you find out that the users suffer from heavy images, try to load images that don't appear on the first screen lazily. In other words:
- Images from the first screen should be loaded as usual
- The rest of the images should have special attributes, to load them when the user's viewport reaches each image.
- To load images we can use any library or our own solution. Here is an article about this method: https://css-tricks.com/the-complete-guide-to-lazy-loading-images/
HTTP2.0
In general, you don't reach a high level of optimization, but it's still important
HTTP2.0 Multiplexing
In case the website downloads a lot of resources HTTP2.0 with multiplexing could help.
Suggest, we have 6 render-blocking resources placed on the same domain. Styles, blocking js code, etc.
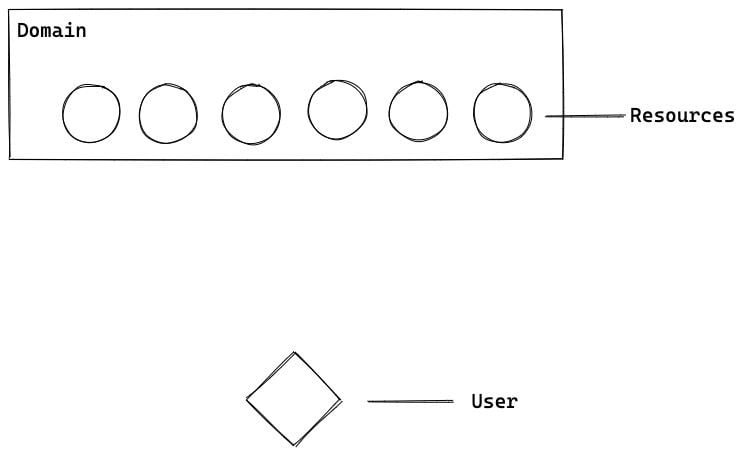
The browser makes parallel request to each resource:

Browsers limit the number of simultaneous requests to the domain in one browser's tab. Hence, some resources will be requested after receiving a response from the previous resource.
Each resource has time-consuming stages like TCP handshake and other costs. They aren't big but exist.
it's why developers reduce the number of resources that are needed to render the page.
What is multiplexing?
Multiplexing allows us to load resources inside the exact one HTTP-request:
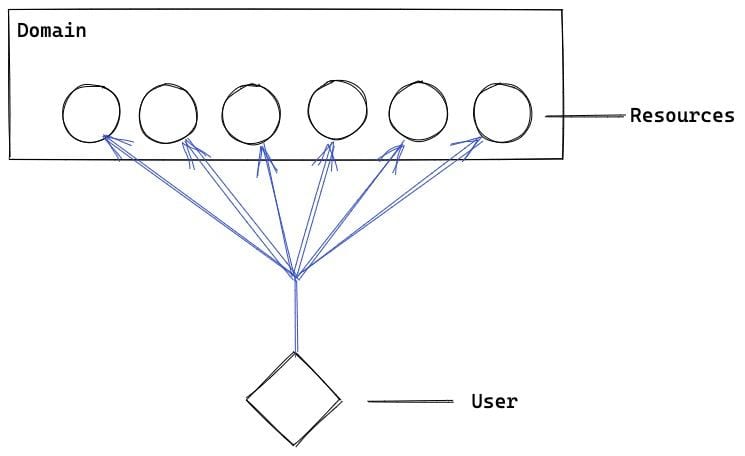
Of course, we could have not the exact 1 request. It could be 2, 3, and so on. Each request loads some resources. It allows us to save time on handshakes, resolves, etc, and we optimize the limitation of simultaneously downloading resources
HTTP2.0 Headers compressing
We haven't had headers compressing before http2.0. HTTP2.0 announced HPACK that is in charge of it. More detailed information: https://tools.ietf.org/html/rfc7541
Sometimes headers could be big. Here is how HPACK works in short:
Huffman coding as an algorithm and 2 dictionaries:
1) Static one — for base headers
2) Dynamic — for custom
HTTP2.0 Server push
For small websites, static ones, or landing pages it's not a problem to implement server push. The idea is simple: we encapsulate the information to our web-server that the user has to download several resources besides the requested page.
Nginx example:
location = /index.html {
http2_push /style.css;
http2_push /bundle.js;
http2_push /image.jpg;
}
Let's check it:

In case you have a big website you have to set up a complex pipe-line when after bundling, chunk names should be listed in some dictionary, which will be used as a base for you nginx htt2_push config.
Resource compressing
The most popular solution is to use gzip or brotli. This website gives a good comparison between these algorithms: https://tools.paulcalvano.com/compression.php

We migrated from gzip to brotli one and a half years ago. The size of our main bundle was reduced from 736 Kb to 657. We saved almost 12%.
The biggest disadvantage of Brotli that it has bigger costs for "packing" data. It's heavier than gzip on average. So you could make a rule on nginx to cache resources that are packed by brotli or put already brotled resources. (the same thing you could do with gzip).
But brotli in most cases is better than gzip. It allows saving 1-1.5 sec of downloading in poor 3G networks, which notably improve both user experience and lighthouse metrics.
Caching
Note: Described method doesn't improve your lighthouse metrics, but it helps for real users. It could improve both FMP and TTI.
The base cache could be turned on using headers. An advanced way is to use the Service worker additionally.
Talking about headers we have 3 params:
1) last-modified or expires
2) ETag
3) Cache-control
The first two params (last-modified and expires) work around the date, the second ETag is a key (or hash-sum) that is used during the request, and if the requested key is the same as the server's one, the server response with 304. In case they are not the same, the server sends the whole resource. It's easy to turn on caching:
location ~* ^.+\.(js|css)$ {
...
etag on;
}
Disk cache is checkable using dev tools:

Cache-control is a strategy of how we're going to cache the resources. We are able to turn it off by setting cache-control: no-cache, which is quite suitable for html requests that change a lot (like search pages). The second strategy is to set a big value for max-age so that data store as long as possible. For our static at hh.ru we use the following:
cache-control: max-age=315360000, public
We release our services often (several times per day for each service). It means, people have to load our new bundles, parse code, and so on several times each day.
To dive deeper how browsers execute code and use caches I advice to read a great article in v8 blog: https://v8.dev/blog/code-caching-for-devs
We are interested in this scheme:
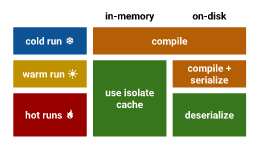
So there are "3 ways" of running our application: cold \ warm, and hot run.
The ideal scenario for us is to run the application in the "hot run" way. It allows us not to spend our time for code compilation. It's enough just to deserialize it.
To get hot run a user has to get to the site 3 times (for the same resources) per 72 hours timeslot. If a user gets to the website only 2 times it will be a warm run, which still compiles the data and serialize it to the disk cache.
But we do have a workaround and can force hot run using Service Worker. The method is the following:
1) Set up Service Worker
2) Subscribe to fetch
3) If fetch is evaluated to get site static, save static into the cache
4) If fetch is evaluated to get cached static resource, send it.
This method forces the disk cache to store the data and to use the hot run starting the second time. Also, it leads to bigger optimization for mobile devices as they reset the regular cache more often than desktops.
Minimal code for Service Worker:
self.addEventListener('fetch', function(event) {
// Cache static resource, but not the images
if (event.request.url.indexOf(staticHost) !== -1 && event.request.url.search(/\.(svg|png|jpeg|jpg|gif)/) === -1) {
return event.respondWith(
// Check whether data in cache
caches.match(event.request).then(function(response) {
if (response) {
return response;
}
// If we don't have the resource in the cache, make a request and cache it
return fetch(event.request).then(function(response) {
caches.open(cacheStatic).then(function(cache) {
cache.add(event.request.url);
});
return response;
});
})
);
}
});
Summing up
We dived into our Critical render path from the client-side (but we don't check such things like DNS resolving, handshakes, DB request, and etc.) We defined steps in which browsers arrange to render a page for users.
We reviewed different optimization methods like content splitting, caching, compressing.
The second part will be dedicated to websites runtime and how browsers "draw" frames.





Top comments (0)